Serverless Databricks — Instant Computing with Zero Admin Overhead

Written by Hassan Sherwani
Head of Data Analytics and Data Science
August 18, 2022
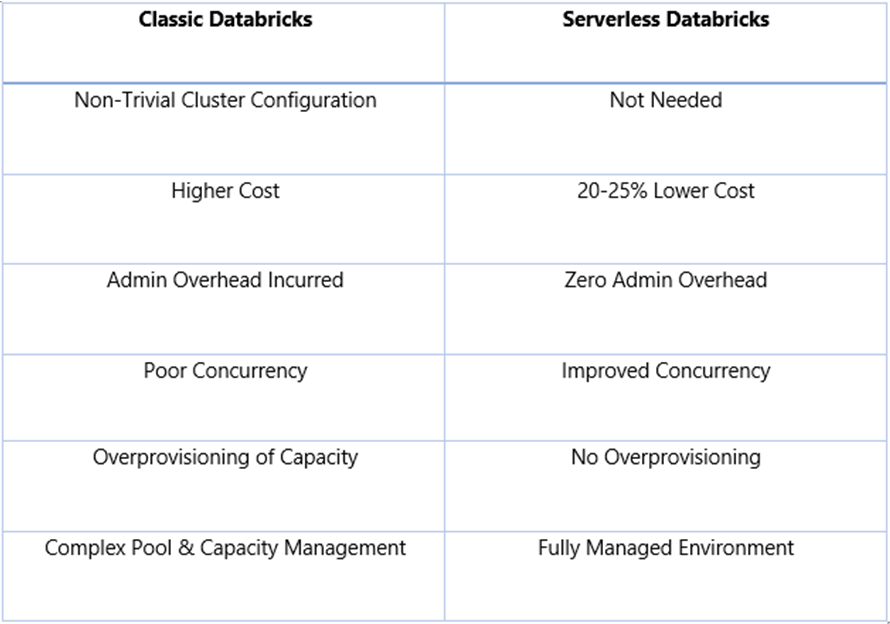
Traditionally, an analyst using the Databricks platform have to create an endpoint to manage the clusters for running queries or accessing BI tools. In addition, they also have to perform a number of other tasks that tend to take up a lot of time and attention, like doing cluster configuration, determining the instance type, and managing the pool and its capacity. Not to mention, one has to wait for several minutes before one can finally use the computation environment.
Such a state of affairs often compels the customers to go for long-running clusters while entailing overprovisioning of resources. Consequently, the users end up paying for their idle resources and needless admin overhead. Keeping these concerns of the customers in mind, Databricks has introduced a Serverless platform that aims to lower the costs and scale up the workloads for its users.
Dive into this blog to know in-depth about what Serverless Databricks has in store for you.
What is Serverless Databricks?
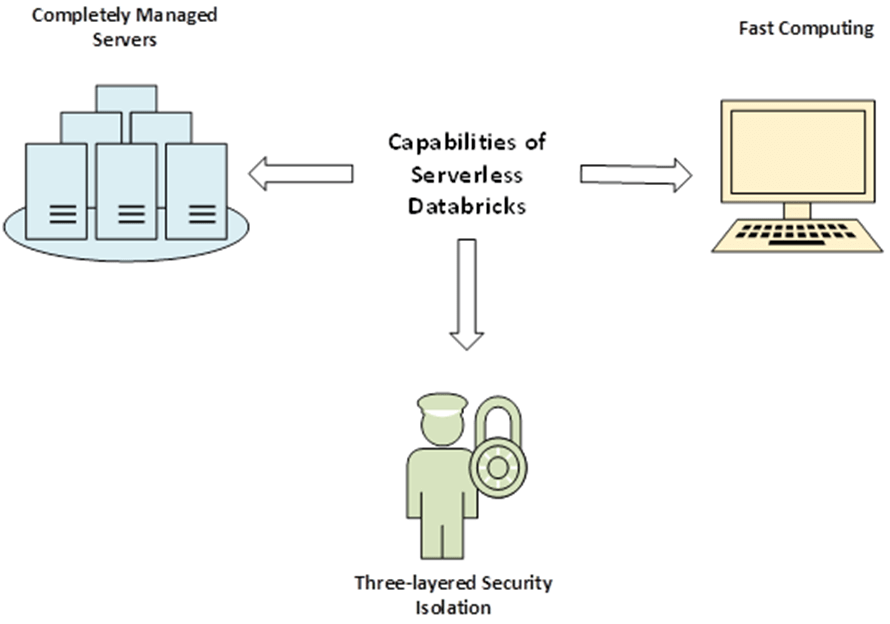
Serverless Databricks platform provides instant endpoints and a completely managed environment without requiring you to monitor servers. In other words, users can not only scale the clusters up and down whenever they like, but they can also trust Databricks to manage their resources remotely. The most significant plus point is that one can begin computing in a matter of seconds without worrying about managing the capacity with the cloud provider.
A pool of database clusters is always up and running in the Serverless environment. The clusters are not assigned to any customer; instead, they are managed by Databricks itself on behalf of the users. In this way, no one is charged for their management. Moreover, the Serverless platform utilizes Spark — one of the most performant engines in the market — to bring speed and improved availability for its users.
The platform has been designed on a Machine Learning model to meet the vast capacity needs of the customers and also make timely predictions to anticipate the change in demands beforehand.
As mentioned earlier, Serverless Databricks aims to eliminate the hurdles previously faced by people while using the traditional Databricks interface for computation. Let’s take a look at a quick comparison of the new and old platforms to erase the doubts.
How Can Serverless Databricks Help You?
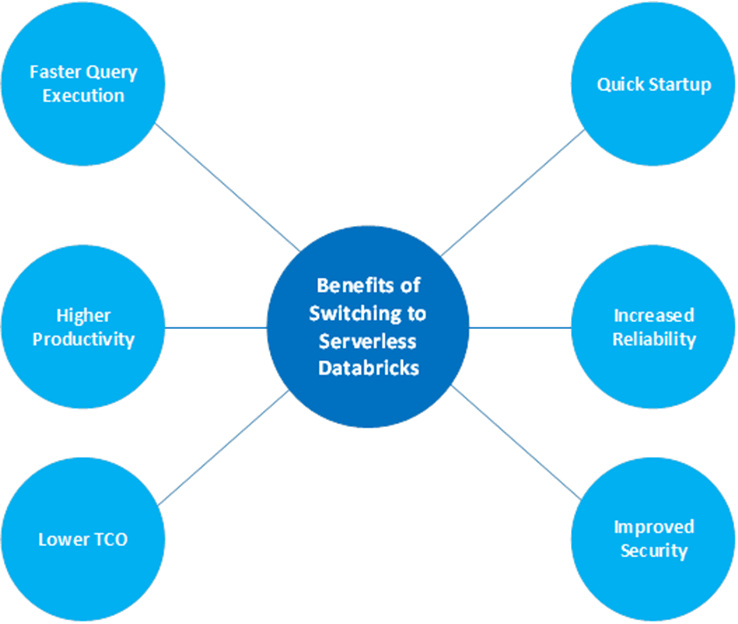
Here’s how Serverless Databricks can benefit you and your business.
Quick Startup
On the traditional Databricks platform, query performance, on average, took about 5 minutes. This compelled the customers to opt for instance pools to cut down the time, which would prove quite expensive. Serverless Databricks takes less than 10 seconds to carry the first query performance and hence ensures a quick startup.
Increased Reliability
Serverless Databricks helps you get rid of the worries related to choosing the appropriate instance types, warm pooling, and administrative simplicity. All you have to do is select an approximate size for your pool. Serverless then chooses your pool by default and optimizes it as well. It also takes care of the subscription sharding.
Reduced Total Cost of Ownership (TCO)
Serverless Databricks brings all the advanced features at less cost. It has been observed that, by switching to the Serverless environment, customers are able to reduce their total cost of ownership up to 20–40%. Furthermore, it should be mentioned that no additional arrangements are required to transfer from a non-serverless compute to a serverless one.
Improved Security of Data
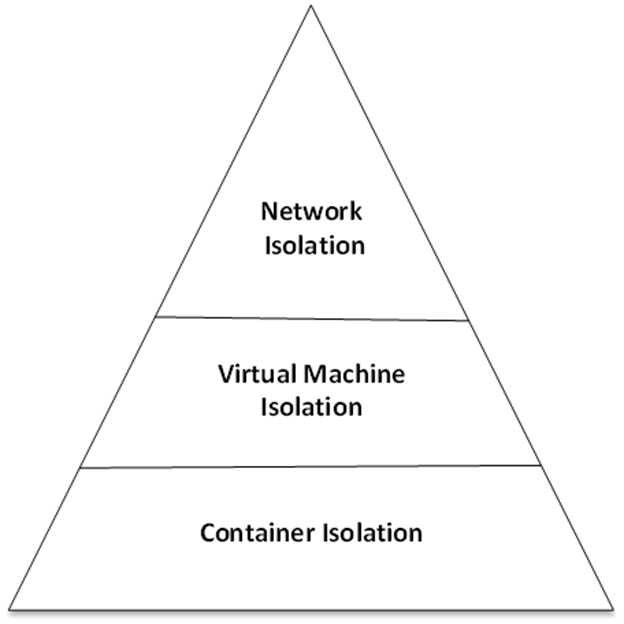
The platform ensures the security of your data by segregating all the clusters you use from those existing on the same data plane but being used by the other tenants. Besides the container boundary, there is also a VM boundary which provides real isolation to the data by prohibiting VM reuse. Finally, a third layer related to network isolation is present, which allows access to only the intra-cluster traffic. Overall, it is a three-layer security isolation system employed to preserve customers’ data.
Elastic Environment
The pool of clusters is highly elastic, meaning they can be scaled up whenever the workload is high and down when there is a lighter workload. To put it differently, one need not worry about the environment’s capacity while performing computation.
Higher Productivity
Since you can start up the environment and access the infrastructure readily, you are able to finish your tasks way faster than normally is possible with classic Databricks. This naturally boosts your productivity and helps you perform efficient ad hoc querying, develop dashboards, and access third-party BI tools.
Conclusion
This blog gives an overview of Serverless Databricks, which provides instant computing with zero admin overhead to its users. By using this technology, users can easily scale their workloads and maintain high productivity trends.
If you have any queries or want to discuss the suitability of the Serverless Databricks platform for your organization, feel free to reach out to the Royal Cyber team. Data Scientists and Analysts at Royal Cyber have specialized knowledge of managing all the services offered by Databricks and can help you optimize the technology for your business needs.
Recent Blogs
 Learn to write effective test cases. Master best practices, templates, and tips to enhance software …Read More »
Learn to write effective test cases. Master best practices, templates, and tips to enhance software …Read More »- In today’s fast-paced digital landscape, seamless data integration is crucial for businessRead More »
- Harness the power of AI with Salesforce Einstein GPT for Service Cloud. Unlock innovative ways …Read More »