
Evaluating the Components of Snowflake Architecture

Written by Hafsa Mustafa
Technical Content Writer
November 13, 2022
Traditional data warehouses work all good and well until they start posing issues when someone tries to load and query data simultaneously, runs complex queries, or starts feeding data from different sources. Such drawbacks lead to inconsistencies that organizations simply cannot afford. Modern businesses need a single source of truth – a central data repository – that reliably gathers all the authentic data on one platform and ensures its availability for data analytics and BI at all times.
Snowflake allays the above-mentioned concerns by presenting a data warehousing platform that provides elasticity, high performance, and scalability through its multi-cluster architecture. Snowflake is a data management system that covers an organization’s data collection, organization, storage, and processing needs. Read on to learn its structure in detail.
Snowflake Architecture
Snowflake is a Software-as-a-Service platform that acts as a data warehouse and runs on the cloud. It does not require manual configuration and is quite cost-effective. Snowflake schema can be described as an extension of star schema, a database with tables that connect multidimensionally – making it look like a literal snowflake.
Snowflake supports both batch and continuous pipelines that can be built in the language of one’s choice. Furthermore, the data can be ingested incrementally or in bulk either incrementally or in bulk. This feature makes Snowflake highly flexible.
To understand Snowflake’s working fully, you must first dig into its data warehouse architecture. Snowflake functions through three layers:
- Cloud Services Layer – the outermost layer
- Compute Layer – the middle, query processing layer
- Database Storage – the innermost layer
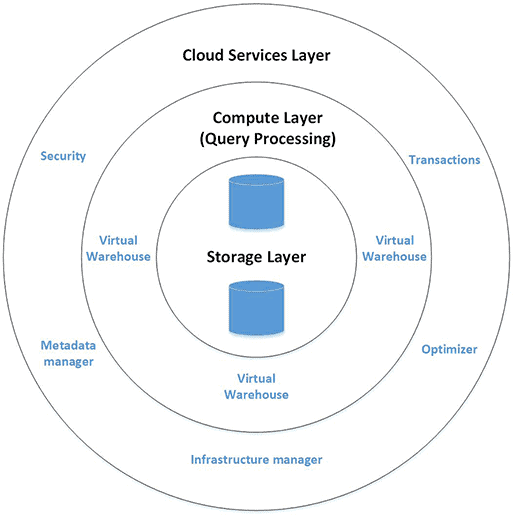
Cloud Services
The cloud services layer acts as the executive or brain of the entire data warehouse architecture. It coordinates all the functions and processes happening within the Snowflake. The cloud layer constitutes multiple services like infrastructure management, access control, data sharing, metadata management, security, authentication, and query optimization.
What makes Snowflake data warehouse architecture really unique is its matchless data-sharing capabilities. Unlike other databases, Snowflake allows its users to share stored data with external parties. It does this by completely decoupling its storage and compute processes. When a need to share arises, Snowflake simply generates a data clone which is actually just a reference to the real data stored in the database.
The services layer contains a metadata store which helps it increase data availability. For instance, there are some commands that don’t require that the warehouse be up and running when you run them. These commands can be about dropping and creating a table or increasing and decreasing the table size. Since it is the outermost layer of the structure, this layer forms the surface that interacts with the user.
Another notable feature of the Services layer is caching. Here, Snowflake generates two types of cache. The Metadata cache contains the key information about tables (i.e., size, references, etc.) and the partitions. The Results cache, on the other hand, holds data about the latest queries. The time limit is 24 hours for a query. Therefore, if you run a query that another user recently ran, you will receive data from the cache memory, not the warehouse itself.
Compute Layer
This layer of Snowflake data warehouse architecture consists of multiple virtual warehouses that ensure significant parallel processing and scaling. Each specialized department can keep a virtual warehouse of its own to store the relevant data. Compute layer brings about the whole process of running queries and retrieving desired data from the warehouse. It also contains a Raw Data Cache that keeps the cloud data that was obtained recently.
Besides allowing users to create as many warehouses as they want, Snowflake also lets them alter the sizes of their warehouses. In other words, when the workload increases, the virtual warehouse can be increased in size to better meet the users’ needs. The warehouse sizes range from X-Small, Small, and Medium to Large, 5X-Large and so on. The number of supported servers also varies accordingly. For instance, X-Small warehouse contains one server for each cluster whereas 3X-Large has as many as 64 servers per cluster. However, it should be mentioned that the bigger your warehouse is, the higher the costs go.
Multi-cluster feature is another distinguishing characteristic of Snowflake. Although the standard setting is to have one cluster along with its servers, users can expand the number of clusters to handle the demand. Snowflake data warehouse architecture has the built-in ability to add new clusters to the network as the demand rises and it also produces well-clustered tables. In this way, concurrency issues do not happen, and the system does not shut down.
Storage Layer
As the title depicts, this area stores all the data in its actual form. The database storage layer compresses the data to store it in blocks. It follows the hybrid columnar storage pattern that makes querying significantly faster and easier. Another way to put it is that the database does not have to go through data rows to fetch the information. Instead, it directly goes to the indicated column and extracts readily what the user needs.
The storage layer in Snowflake works independently of the compute layer. This ultimately ensures non-disruptive scalability in the environment, meaning there is no need to redistribute data in case of higher concurrency. In addition, by providing simultaneous data access, Snowflake ensures that no resource contention occurs. However, being independent does not mean that the storage layer is totally cut off from the rest of the layers. In fact, the query processing and storage layer regularly interact to stay in sync and integrated.
What Makes Snowflake Unique?
Let’s quickly go through the desirable features of Snowflake that give it an edge in the market:
- Its user interface is highly user-friendly, i.e., you need not be a tech-savvy person to use Snowflake.
- The Snowpipe feature of Snowflake allows its users to create batches of data in stages if large volumes of data are coming at high speed. The Snowpipe then copies this data into the database. This allows the user to manage and feed the data gradually.
- One can also drop or un-drop a table in the Snowflake. In this way, data is not unintentionally lost.
- The Fail Safe feature of Snowflake gives the users a grace period of one week in which they can recover the discarded data.
- Using the Time Travel option, timestamps and query ids can retrieve the data that was added on a particular date in the past.
- Snowflake unites data warehouse, data mart, and data lake in one place.
- Due to its metadata facility, the platform does not charge you if you make copies of your tables (through cloning).
Final Comments
If you have any queries regarding this popular data warehouse platform, feel free to contact the Royal Cyber team to get your questions answered. Our experts have extensive knowledge and experience of working with modern data architectures and utilizing them to design innovative solutions for unique business needs.
In this blog, we discussed the architecture and functioning of Snowflake data warehouse in detail. Snowflake considerably simplifies data management for IT personnel by providing a central data repository. It is fast becoming a trusted platform for business enterprises.
Recent Blogs
 An Insight into ServiceNow Hardware Asset Management (HAM) Ramya Priya Balasubramanian Practice Head ServiceNow Gain …Read More »
An Insight into ServiceNow Hardware Asset Management (HAM) Ramya Priya Balasubramanian Practice Head ServiceNow Gain …Read More »- Learn to write effective test cases. Master best practices, templates, and tips to enhance software …Read More »
- In today’s fast-paced digital landscape, seamless data integration is crucial for businessRead More »


