
MLflow 2.0 - A Scalable Platform for Managing ML Lifecycle

Written by Hafsa Mustafa
Content Writer
October 6, 2022
While MLflow, launched in 2018, was doing a remarkable job in assisting users with deploying and monitoring Machine Learning models, Databricks is releasing a second version of the framework that also includes MLflow Pipelines — an addition that will enable the users to see their ML models successfully through the production phase. Dive into this blog to know in detail about the new version is different from the previous one.
What is MLflow Pipelines?
MLflow Pipelines is a framework that accelerates the production and execution of models by providing model-specific production-grade ML pipeline templates. It contains certain features that allow its users to codify their ML processes and standardize them. In this way, it ultimately simplifies and speeds up the MLOps process for any organization. The major components of MLflow that are being rolled out are:
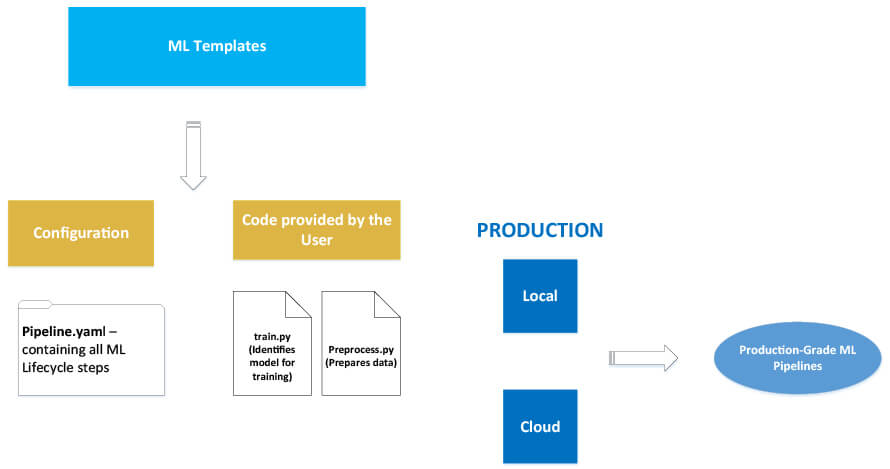
Pipelines
Pipelines contain templates that demonstrate all the steps one needs to take to complete their ML models. In other words, this component walks you through the end-to-end process of MLOps and hence, enables different teams to work on various steps independently without facing needless delays or roadblocks.
Steps
A step is an individual task that gets a specific job done. For instance, it can be related to data acquisition, analysis, feature transformation, or model evaluation. These steps have been presented as parts of a larger process, i.e., data pipelines through an interconnected interface, and can be used repeatedly. Moreover, one can utilize Python code or YAML configuration to customize the steps to meet individual needs and requirements.
Pipeline Templates
These are the pre-established different pipeline templates that can be used for various purposes, for instance, regression, inference, etc. They contain relevant standard procedures as best practices for solving multiple ML-related issues and operations. However, one can also create new templates according to their requirements.
Why MLflow Pipelines?
Utilizing data for models, developing the Machine Learning models themselves, and finally running these models into production can prove to be a tricky thing. Not only this, but scaling the deployed ML models also often seems to be a hard nut to crack. All of these jobs require a significant amount of manual effort and time. Let’s take a brief overview of why one should use MLflow version 2.0 to support their end-to-end ML lifecycles.
Accelerates Production
By providing pre-defined templates and allowing data scientists to design codes that do not require restructuring during deployment, Mlflow pipelines bring acceleration and uniformity to ML programs. You can closely manage your models by employing the principles of data engineering and reuse your pipelines in different environments — with reliable results.
Experimentation without Repetition
Having to do a job repetitively is not only tiring but also time-taking. MLflow pipelines take care of this problem by memorizing the steps of the pipelines that have been run already. In this way, next time you run the same pipeline, the platform only focuses on the new additions hence saving time and energy. Data scientists can now conduct experiments, do model training, and repeated testing without worrying about the usual lengthy procedures.
No Need to Worry about Boilerplate Code
MLflow pipelines contain boilerplate code, i.e., the code that is used in multiple places unchanged, that enables the users to perform the tasks without having to write the same code every single time. One can then focus on writing and altering specific production-grade ML code that demands attention. In addition to that, the platform also provides visualization to help data scientists troubleshoot faults.
Easier Tracking
MLflow pipelines make tracking past actions easier by storing metadata related to every pipeline and its runs, codes, and whatnot. In this way, the users can easily observe the old runs and compare the outcomes of different executions to keep track and identify any room for improvement.
Conclusion
This blog gives an overview of what MLflow 2.0 is and how it can help the data scientists like you in improving your Machine Learning lifecycles and deploying models. If you have queries on the subject, you can contact data scientists or analysts at Royal Cyber to get them answered. Our team has extensive hands-on experience working with MLflow and other modern data platforms like Databricks and Azure Synapse.
Recent Blogs
 An Insight into ServiceNow Hardware Asset Management (HAM) Ramya Priya Balasubramanian Practice Head ServiceNow Gain …Read More »
An Insight into ServiceNow Hardware Asset Management (HAM) Ramya Priya Balasubramanian Practice Head ServiceNow Gain …Read More »- Learn to write effective test cases. Master best practices, templates, and tips to enhance software …Read More »
- In today’s fast-paced digital landscape, seamless data integration is crucial for businessRead More »


